NFL2022_stuffs <- read_csv('https://bcdanl.github.io/data/NFL2022_stuffs.csv')My Github repository: https://github.com/annbrennan/annbrennan.github.io
The following is the data.frame for Question 2.
rmarkdown::paged_table(NFL2022_stuffs) Variable Description
play_id: Numeric play identifier that when used with game_id and drive provides the unique identifier for a single play game_id: Ten digit identifier for NFL game. drive: Numeric drive number in the game. week: Season week. posteam: String abbreviation for the team with possession. qtr: Quarter of the game (5 is overtime). half_seconds_remaining: Numeric seconds remaining in the half. down: The down for the given play. Basically you get four attempts (aka downs) to move the ball 10 yards (by either running with it or passing it). If you make 10 yards then you get another set of four downs. pass: Binary indicator if the play was a pass play. wp: Estimated winning probability for the posteam given the current situation at the start of the given play.
Q2a
In data.frame, NFL2022_stuffs, remove observations for which values of posteam is missing.
NFL2022_stuffs <- na.omit(NFL2022_stuffs)Q2b
Summarize the mean value of pass for each posteam when all the following conditions hold: 1. wp is greater than 20% and less than 75%; 2. down is less than or equal to 2; and 3. half_seconds_remaining is greater than 120.
q2b <- NFL2022_stuffs %>%
filter(wp > 0.2 & wp < 0.75 & down <= 2 & half_seconds_remaining > 120) %>%
group_by(posteam) %>%
summarise(mean_pass = mean(pass, na.rm = TRUE))Q2c
Provide both (1) a ggplot code with geom_point() using the resulting data.frame in Q2b and (2) a simple comments to describe the mean value of pass for each posteam.
In the ggplot, reorder the posteam categories based on the mean value of pass in ascending or in descending order.
ggplot(q2b, aes(x = reorder(posteam, mean_pass), y = mean_pass)) +
geom_point() +
labs(x = "team with possession",
y = "percentage of pass plays") +
coord_flip()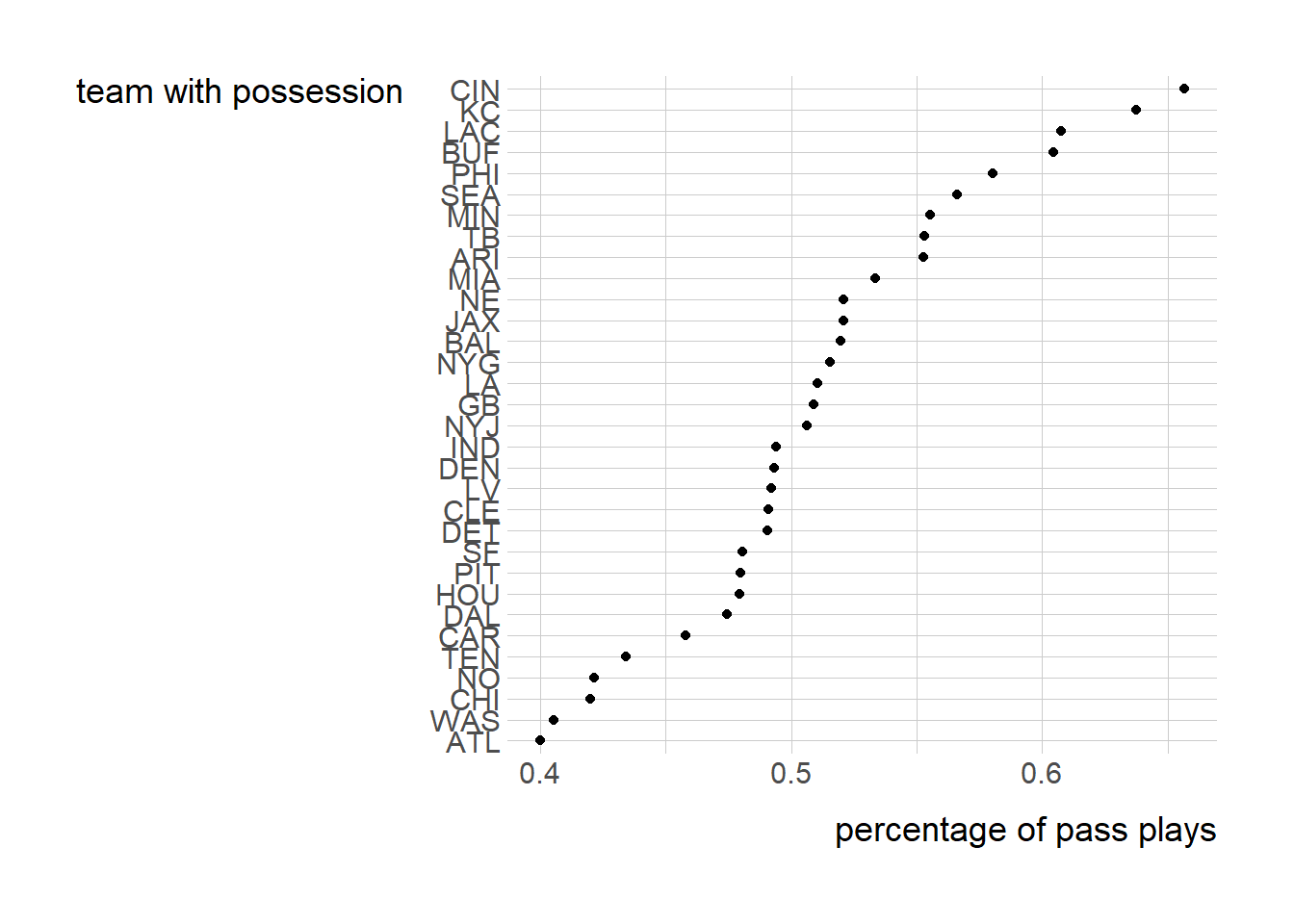
The teams listed at the top of the graph have the largest mean value of pass, whereas the teams at the bottom have the smallest mean value of pass. The teams are in descending order based on mean value of pass. CIN and KC have the highest mean value of pass. WAS and ATL have the lowest mean value of pass.
Q2d
Consider the following data.frame, NFL2022_epa:
NFL2022_epa <- read_csv('https://bcdanl.github.io/data/NFL2022_epa.csv')Create the data.frame, NFL2022_stuffs_EPA, that includes: - All the variables in the data.frame, NFL2022_stuffs; - The variables, passer, receiver, and epa, from the data.frame, NFL2022_epa. by joining the two data.frames.
In the resulting data.frame, NFL2022_stuffs_EPA, remove observations with NA in passer.
NFL2022_stuffs_EPA <- left_join(NFL2022_stuffs, NFL2022_epa[, c("play_id", "passer", "receiver", "epa")], by = "play_id")
NFL2022_stuffs_EPA <- NFL2022_stuffs_EPA %>%
filter(!is.na(passer))Q2e
Provide both (1) a single ggplot and (2) a simple comment to describe the NFL weekly trend of weekly mean value of epa for each of the following two passers, 1. “J.Allen” 2. “P.Mahomes”
q2e <- NFL2022_stuffs_EPA %>%
filter(passer %in% c("J.Allen", "P.Mahomes"))
ggplot(q2e, aes(x = week, y = epa, color = passer)) +
geom_line(stat = "summary", fun = "mean") +
labs(x = "Week",
y = "Mean EPA",
color = "Passer") + scale_color_manual(values = c("J.Allen" = "blue", "P.Mahomes" = "red"))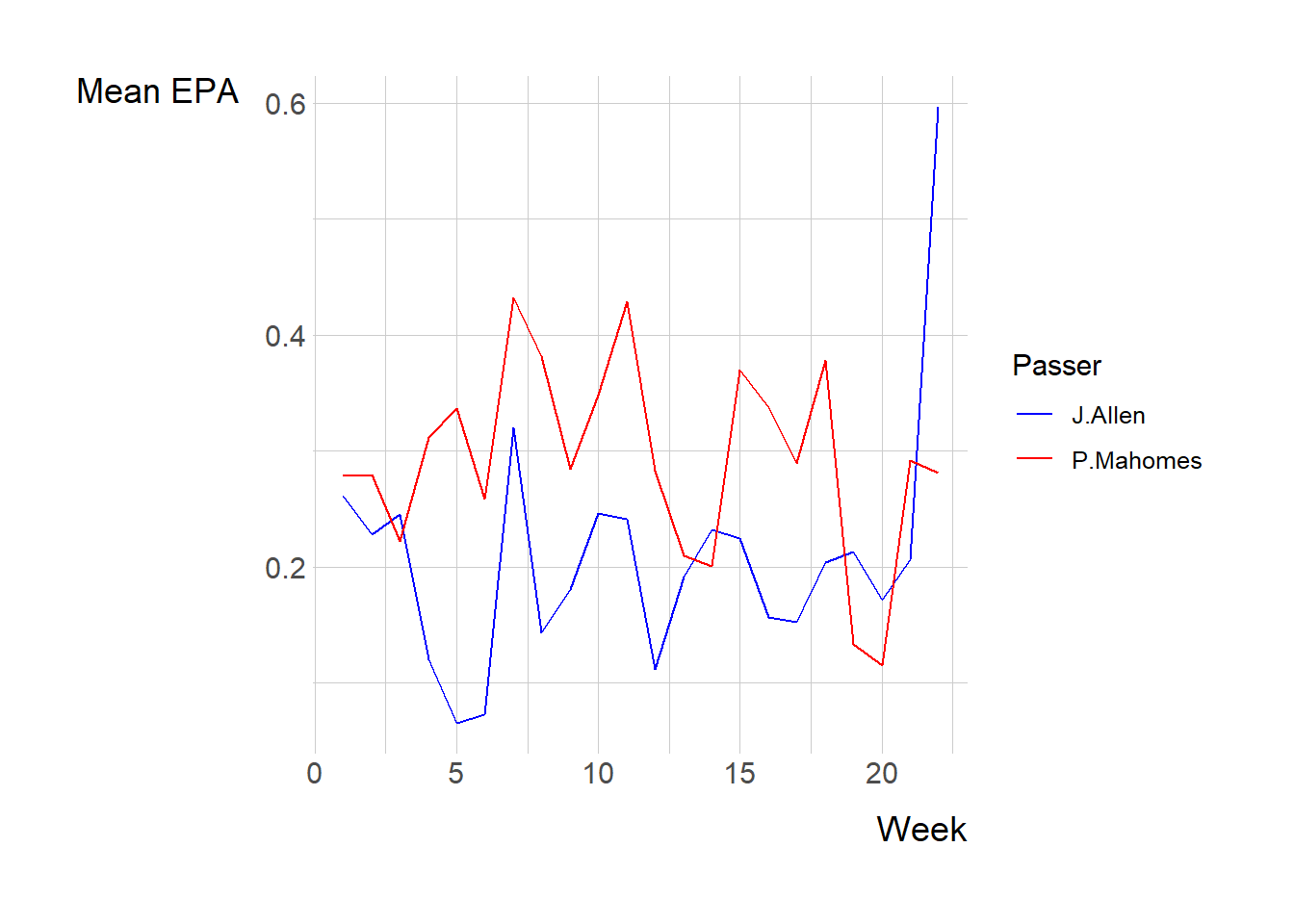
Overall, P. Mahomes generally had a higher mean EPA than J. Allen. However, in the most recent weeks, J. Allen’s mean EPA has risen significantly and is now much higher than P. Mahomes. Meanwhile, P. Mahomes’ mean EPA decreased slightly.
Q2f
Calculate the difference between the mean value of epa for “J.Allen” the mean value of epa for “P.Mahomes” for each value of week.
mean_epa_by_week <- q2e %>%
group_by(passer, week) %>%
summarise(mean_epa = mean(epa, na.rm = TRUE)) %>%
pivot_wider(names_from = passer, values_from = mean_epa)
mean_epa_by_week$epa_difference <- mean_epa_by_week$`J.Allen` - mean_epa_by_week$`P.Mahomes`Q2g
Summarize the resulting data.frame in Q2d, with the following four variables:
- posteam: String abbreviation for the team with possession.
- passer: Name of the player who passed a ball to a receiver by initially taking a three-step drop, and backpedaling into the pocket to make a pass. (Mostly, they are quarterbacks.)
- mean_epa: Mean value of epa in 2022 for each passer
- n_pass: Number of observations for each passer
Then find the top 10 NFL passers in 2022 in terms of the mean value of epa, conditioning that n_pass must be greater than or equal to the third quantile level of n_pass.
summary <- NFL2022_stuffs_EPA %>%
group_by(posteam, passer) %>%
summarise(mean_epa = mean(epa, na.rm = TRUE),
n_pass = n())
third_quantile <- quantile(summary$n_pass, 0.75)
q2f <- summary %>%
filter(n_pass >= third_quantile) %>%
arrange(desc(mean_epa)) %>%
slice_head(n = 10)