from google.colab import data_table
data_table.enable_dataframe_formatter()
import pandas as pd
import numpy as np
from tabulate import tabulate # for table summary
import scipy.stats as stats
from scipy.stats import norm
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm # for lowess smoothing
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import roc_curve
from pyspark.sql import SparkSession
from pyspark.sql.functions import rand, col, pow, mean, avg, when, log, sqrt, exp
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression, GeneralizedLinearRegression
from pyspark.ml.evaluation import BinaryClassificationEvaluator
spark = SparkSession.builder.master("local[*]").getOrCreate()In this post, we will be considering the homes DataFrame from the 2004 American Housing Survey. This contains data on home values, demographics, schools, income, finance, mortgages, sales, neighborhood characteristics, noise, smells, state geography, and urban classification. We will be applying Linear Regression and Logistic Regression models in order to analyze how different factors impact or predict home value.
Loading Packages and Settings
UDFs
We will be using a variety of User Defined Functions (UDFs) in order to perform functions necessary for our Logistic Regression Models. We will define our UDFs before we begin.
marginal_effects
def marginal_effects(model, means):
"""
Compute marginal effects for all predictors in a PySpark GeneralizedLinearRegression model (logit)
and return a formatted table with statistical significance and standard errors.
Parameters:
model: Fitted GeneralizedLinearRegression model (with binomial family and logit link).
means: List of mean values for the predictor variables.
Returns:
- A formatted string containing the marginal effects table.
- A Pandas DataFrame with marginal effects, standard errors, confidence intervals, and significance stars.
"""
global assembler_predictors # Use the global assembler_predictors list
# Extract model coefficients, standard errors, and intercept
coeffs = np.array(model.coefficients)
std_errors = np.array(model.summary.coefficientStandardErrors)
intercept = model.intercept
# Compute linear combination of means and coefficients (XB)
XB = np.dot(means, coeffs) + intercept
# Compute derivative of logistic function (G'(XB))
G_prime_XB = np.exp(XB) / ((1 + np.exp(XB)) ** 2)
# Helper: significance stars.
def significance_stars(p):
if p < 0.01:
return "***"
elif p < 0.05:
return "**"
elif p < 0.1:
return "*"
else:
return ""
# Create lists to store results
results = []
df_results = [] # For Pandas DataFrame
for i, predictor in enumerate(assembler_predictors):
# Compute marginal effect
marginal_effect = G_prime_XB * coeffs[i]
# Compute standard error of the marginal effect
std_error = G_prime_XB * std_errors[i]
# Compute z-score and p-value
z_score = marginal_effect / std_error if std_error != 0 else np.nan
p_value = 2 * (1 - norm.cdf(abs(z_score))) if not np.isnan(z_score) else np.nan
# Compute confidence interval (95%)
ci_lower = marginal_effect - 1.96 * std_error
ci_upper = marginal_effect + 1.96 * std_error
# Append results for table formatting
results.append([
predictor,
f"{marginal_effect: .4f}",
significance_stars(p_value),
f"{std_error: .4f}",
f"{ci_lower: .4f}",
f"{ci_upper: .4f}"
])
# Append results for Pandas DataFrame
df_results.append({
"Variable": predictor,
"Marginal Effect": marginal_effect,
"Significance": significance_stars(p_value),
"Std. Error": std_error,
"95% CI Lower": ci_lower,
"95% CI Upper": ci_upper
})
# Convert results to formatted table
table_str = tabulate(results, headers=["Variable", "Marginal Effect", "Significance", "Std. Error", "95% CI Lower", "95% CI Upper"],
tablefmt="pretty", colalign=("left", "decimal", "left", "decimal", "decimal", "decimal"))
# Convert results to Pandas DataFrame
df_results = pd.DataFrame(df_results)
return table_str, df_results
# Example usage:
# means = [0.5, 30] # Mean values for x1 and x2
# assembler_predictors = ['x1', 'x2'] # Define globally before calling the function
# table_output, df_output = marginal_effects(fitted_model, means)
# print(table_output)
# display(df_output)regression_table
def regression_table(model, assembler):
"""
Creates a formatted regression table from a fitted LinearRegression model and its VectorAssembler.
If the model’s labelCol (retrieved using getLabelCol()) starts with "log", an extra column showing np.exp(coeff)
is added immediately after the beta estimate column for predictor rows. Additionally, np.exp() of the 95% CI
Lower and Upper bounds is also added unless the predictor's name includes "log_". The Intercept row does not
include exponentiated values.
When labelCol starts with "log", the columns are ordered as:
y: [label] | Beta | Exp(Beta) | Sig. | Std. Error | p-value | 95% CI Lower | 95% CI Upper | Exp(95% CI Lower) | Exp(95% CI Upper)
Otherwise, the columns are:
y: [label] | Beta | Sig. | Std. Error | p-value | 95% CI Lower | 95% CI Upper
Parameters:
model: A fitted LinearRegression model (with a .summary attribute and a labelCol).
assembler: The VectorAssembler used to assemble the features for the model.
Returns:
A formatted string containing the regression table.
"""
# Determine if we should display exponential values for coefficients.
is_log = model.getLabelCol().lower().startswith("log")
# Extract coefficients and standard errors as NumPy arrays.
coeffs = model.coefficients.toArray()
std_errors_all = np.array(model.summary.coefficientStandardErrors)
# Check if the intercept's standard error is included (one extra element).
if len(std_errors_all) == len(coeffs) + 1:
intercept_se = std_errors_all[0]
std_errors = std_errors_all[1:]
else:
intercept_se = None
std_errors = std_errors_all
# Use provided tValues and pValues.
df = model.summary.numInstances - len(coeffs) - 1
t_critical = stats.t.ppf(0.975, df)
p_values = model.summary.pValues
# Helper: significance stars.
def significance_stars(p):
if p < 0.01:
return "***"
elif p < 0.05:
return "**"
elif p < 0.1:
return "*"
else:
return ""
# Build table rows for each feature.
table = []
for feature, beta, se, p in zip(assembler.getInputCols(), coeffs, std_errors, p_values):
ci_lower = beta - t_critical * se
ci_upper = beta + t_critical * se
# Check if predictor contains "log_" to determine if exponentiation should be applied
apply_exp = is_log and "log_" not in feature.lower()
exp_beta = np.exp(beta) if apply_exp else ""
exp_ci_lower = np.exp(ci_lower) if apply_exp else ""
exp_ci_upper = np.exp(ci_upper) if apply_exp else ""
if is_log:
table.append([
feature, # Predictor name
beta, # Beta estimate
exp_beta, # Exponential of beta (or blank)
significance_stars(p),
se,
p,
ci_lower,
ci_upper,
exp_ci_lower, # Exponential of 95% CI lower bound
exp_ci_upper # Exponential of 95% CI upper bound
])
else:
table.append([
feature,
beta,
significance_stars(p),
se,
p,
ci_lower,
ci_upper
])
# Process intercept.
if intercept_se is not None:
intercept_p = model.summary.pValues[0] if model.summary.pValues is not None else None
intercept_sig = significance_stars(intercept_p)
ci_intercept_lower = model.intercept - t_critical * intercept_se
ci_intercept_upper = model.intercept + t_critical * intercept_se
else:
intercept_sig = ""
ci_intercept_lower = ""
ci_intercept_upper = ""
intercept_se = ""
if is_log:
table.append([
"Intercept",
model.intercept,
"", # Removed np.exp(model.intercept)
intercept_sig,
intercept_se,
"",
ci_intercept_lower,
"",
ci_intercept_upper,
""
])
else:
table.append([
"Intercept",
model.intercept,
intercept_sig,
intercept_se,
"",
ci_intercept_lower,
ci_intercept_upper
])
# Append overall model metrics.
if is_log:
table.append(["Observations", model.summary.numInstances, "", "", "", "", "", "", "", ""])
table.append(["R²", model.summary.r2, "", "", "", "", "", "", "", ""])
table.append(["RMSE", model.summary.rootMeanSquaredError, "", "", "", "", "", "", "", ""])
else:
table.append(["Observations", model.summary.numInstances, "", "", "", "", ""])
table.append(["R²", model.summary.r2, "", "", "", "", ""])
table.append(["RMSE", model.summary.rootMeanSquaredError, "", "", "", "", ""])
# Format the table rows.
formatted_table = []
for row in table:
formatted_row = []
for i, item in enumerate(row):
# Format Observations as integer with commas.
if row[0] == "Observations" and i == 1 and isinstance(item, (int, float, np.floating)) and item != "":
formatted_row.append(f"{int(item):,}")
elif isinstance(item, (int, float, np.floating)) and item != "":
if is_log:
# When is_log, the columns are:
# 0: Metric, 1: Beta, 2: Exp(Beta), 3: Sig, 4: Std. Error, 5: p-value,
# 6: 95% CI Lower, 7: 95% CI Upper, 8: Exp(95% CI Lower), 9: Exp(95% CI Upper).
if i in [1, 2, 4, 6, 7, 8, 9]:
formatted_row.append(f"{item:,.3f}")
elif i == 5:
formatted_row.append(f"{item:.3f}")
else:
formatted_row.append(f"{item:.3f}")
else:
# When not is_log, the columns are:
# 0: Metric, 1: Beta, 2: Sig, 3: Std. Error, 4: p-value, 5: 95% CI Lower, 6: 95% CI Upper.
if i in [1, 3, 5, 6]:
formatted_row.append(f"{item:,.3f}")
elif i == 4:
formatted_row.append(f"{item:.3f}")
else:
formatted_row.append(f"{item:.3f}")
else:
formatted_row.append(item)
formatted_table.append(formatted_row)
# Set header and column alignment based on whether label starts with "log"
if is_log:
headers = [
f"y: {model.getLabelCol()}",
"Beta", "Exp(Beta)", "Sig.", "Std. Error", "p-value",
"95% CI Lower", "95% CI Upper", "Exp(95% CI Lower)", "Exp(95% CI Upper)"
]
colalign = ("left", "right", "right", "center", "right", "right", "right", "right", "right", "right")
else:
headers = [f"y: {model.getLabelCol()}", "Beta", "Sig.", "Std. Error", "p-value", "95% CI Lower", "95% CI Upper"]
colalign = ("left", "right", "center", "right", "right", "right", "right")
table_str = tabulate(
formatted_table,
headers=headers,
tablefmt="pretty",
colalign=colalign
)
# Insert a dashed line after the Intercept row.
lines = table_str.split("\n")
dash_line = '-' * len(lines[0])
for i, line in enumerate(lines):
if "Intercept" in line and not line.strip().startswith('+'):
lines.insert(i+1, dash_line)
break
return "\n".join(lines)
# Example usage:
# print(regression_table(model_1, assembler_1))add_dummy_variables
def add_dummy_variables(var_name, reference_level, category_order=None):
"""
Creates dummy variables for the specified column in the global DataFrames dtrain and dtest.
Allows manual setting of category order.
Parameters:
var_name (str): The name of the categorical column (e.g., "borough_name").
reference_level (int): Index of the category to be used as the reference (dummy omitted).
category_order (list, optional): List of categories in the desired order. If None, categories are sorted.
Returns:
dummy_cols (list): List of dummy column names excluding the reference category.
ref_category (str): The category chosen as the reference.
"""
global dtrain, dtest
# Get distinct categories from the training set.
categories = dtrain.select(var_name).distinct().rdd.flatMap(lambda x: x).collect()
# Convert booleans to strings if present.
categories = [str(c) if isinstance(c, bool) else c for c in categories]
# Use manual category order if provided; otherwise, sort categories.
if category_order:
# Ensure all categories are present in the user-defined order
missing = set(categories) - set(category_order)
if missing:
raise ValueError(f"These categories are missing from your custom order: {missing}")
categories = category_order
else:
categories = sorted(categories)
# Validate reference_level
if reference_level < 0 or reference_level >= len(categories):
raise ValueError(f"reference_level must be between 0 and {len(categories) - 1}")
# Define the reference category
ref_category = categories[reference_level]
print("Reference category (dummy omitted):", ref_category)
# Create dummy variables for all categories
for cat in categories:
dummy_col_name = var_name + "_" + str(cat).replace(" ", "_")
dtrain = dtrain.withColumn(dummy_col_name, when(col(var_name) == cat, 1).otherwise(0))
dtest = dtest.withColumn(dummy_col_name, when(col(var_name) == cat, 1).otherwise(0))
# List of dummy columns, excluding the reference category
dummy_cols = [var_name + "_" + str(cat).replace(" ", "_") for cat in categories if cat != ref_category]
return dummy_cols, ref_category
# Example usage without category_order:
# dummy_cols_year, ref_category_year = add_dummy_variables('year', 0)
# Example usage with category_order:
# custom_order_wkday = ['sunday', 'monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday']
# dummy_cols_wkday, ref_category_wkday = add_dummy_variables('wkday', reference_level=0, category_order = custom_order_wkday)add_interaction_terms
def add_interaction_terms(var_list1, var_list2, var_list3=None):
"""
Creates interaction term columns in the global DataFrames dtrain and dtest.
For two sets of variable names (which may represent categorical (dummy) or continuous variables),
this function creates two-way interactions by multiplying each variable in var_list1 with each
variable in var_list2.
Optionally, if a third list of variable names (var_list3) is provided, the function also creates
three-way interactions among each variable in var_list1, each variable in var_list2, and each variable
in var_list3.
Parameters:
var_list1 (list): List of column names for the first set of variables.
var_list2 (list): List of column names for the second set of variables.
var_list3 (list, optional): List of column names for the third set of variables for three-way interactions.
Returns:
A flat list of new interaction column names.
"""
global dtrain, dtest
interaction_cols = []
# Create two-way interactions between var_list1 and var_list2.
for var1 in var_list1:
for var2 in var_list2:
col_name = f"{var1}_*_{var2}"
dtrain = dtrain.withColumn(col_name, col(var1).cast("double") * col(var2).cast("double"))
dtest = dtest.withColumn(col_name, col(var1).cast("double") * col(var2).cast("double"))
interaction_cols.append(col_name)
# Create two-way interactions between var_list1 and var_list3.
if var_list3 is not None:
for var1 in var_list1:
for var3 in var_list3:
col_name = f"{var1}_*_{var3}"
dtrain = dtrain.withColumn(col_name, col(var1).cast("double") * col(var3).cast("double"))
dtest = dtest.withColumn(col_name, col(var1).cast("double") * col(var3).cast("double"))
interaction_cols.append(col_name)
# Create two-way interactions between var_list2 and var_list3.
if var_list3 is not None:
for var2 in var_list2:
for var3 in var_list3:
col_name = f"{var2}_*_{var3}"
dtrain = dtrain.withColumn(col_name, col(var2).cast("double") * col(var3).cast("double"))
dtest = dtest.withColumn(col_name, col(var2).cast("double") * col(var3).cast("double"))
interaction_cols.append(col_name)
# If a third list is provided, create three-way interactions.
if var_list3 is not None:
for var1 in var_list1:
for var2 in var_list2:
for var3 in var_list3:
col_name = f"{var1}_*_{var2}_*_{var3}"
dtrain = dtrain.withColumn(col_name, col(var1).cast("double") * col(var2).cast("double") * col(var3).cast("double"))
dtest = dtest.withColumn(col_name, col(var1).cast("double") * col(var2).cast("double") * col(var3).cast("double"))
interaction_cols.append(col_name)
return interaction_cols
# Example
# interaction_cols_brand_price = add_interaction_terms(dummy_cols_brand, ['log_price'])
# interaction_cols_brand_ad_price = add_interaction_terms(dummy_cols_brand, dummy_cols_ad, ['log_price'])compare_reg_models
def compare_reg_models(models, assemblers, names=None):
"""
Produces a single formatted table comparing multiple regression models.
For each predictor (the union across models, ordered by first appearance), the table shows
the beta estimate (with significance stars) from each model (blank if not used).
For a predictor, if a model's outcome (model.getLabelCol()) starts with "log", the cell displays
both the beta and its exponential (separated by " / "), except when the predictor's name includes "log_".
(The intercept row does not display exp(.))
Additional rows for Intercept, Observations, R², and RMSE are appended.
The header's first column is labeled "Predictor", and subsequent columns are
"y: [outcome] ([name])" for each model.
The table is produced in grid format (with vertical lines). A dashed line (using '-' characters)
is inserted at the top, immediately after the header, and at the bottom.
Additionally, immediately after the Intercept row, the border line is replaced with one using '='
(to appear as, for example, "+==============================================+==========================+...").
Parameters:
models (list): List of fitted LinearRegression models.
assemblers (list): List of corresponding VectorAssembler objects.
names (list, optional): List of model names; defaults to "Model 1", "Model 2", etc.
Returns:
A formatted string containing the combined regression table.
"""
# Default model names.
if names is None:
names = [f"Model {i+1}" for i in range(len(models))]
# For each model, get outcome and determine if that model is log-transformed.
outcomes = [m.getLabelCol() for m in models]
is_log_flags = [out.lower().startswith("log") for out in outcomes]
# Build an ordered union of predictors based on first appearance.
ordered_predictors = []
for assembler in assemblers:
for feat in assembler.getInputCols():
if feat not in ordered_predictors:
ordered_predictors.append(feat)
# Helper for significance stars.
def significance_stars(p):
if p is None:
return ""
if p < 0.01:
return "***"
elif p < 0.05:
return "**"
elif p < 0.1:
return "*"
else:
return ""
# Build rows for each predictor.
rows = []
for feat in ordered_predictors:
row = [feat]
for m, a, is_log in zip(models, assemblers, is_log_flags):
feats_model = a.getInputCols()
if feat in feats_model:
idx = feats_model.index(feat)
beta = m.coefficients.toArray()[idx]
p_val = m.summary.pValues[idx] if m.summary.pValues is not None else None
stars = significance_stars(p_val)
cell = f"{beta:.3f}{stars}"
# Only add exp(beta) if model is log and predictor name does NOT include "log_"
if is_log and ("log_" not in feat.lower()):
cell += f" / {np.exp(beta):,.3f}"
row.append(cell)
else:
row.append("")
rows.append(row)
# Build intercept row (do NOT compute exp(intercept)).
intercept_row = ["Intercept"]
for m in models:
std_all = np.array(m.summary.coefficientStandardErrors)
coeffs = m.coefficients.toArray()
if len(std_all) == len(coeffs) + 1:
intercept_p = m.summary.pValues[0] if m.summary.pValues is not None else None
else:
intercept_p = None
sig = significance_stars(intercept_p)
cell = f"{m.intercept:.3f}{sig}"
intercept_row.append(cell)
rows.append(intercept_row)
# Add Observations row.
obs_row = ["Observations"]
for m in models:
obs = m.summary.numInstances
obs_row.append(f"{int(obs):,}")
rows.append(obs_row)
# Add R² row.
r2_row = ["R²"]
for m in models:
r2_row.append(f"{m.summary.r2:.3f}")
rows.append(r2_row)
# Add RMSE row.
rmse_row = ["RMSE"]
for m in models:
rmse_row.append(f"{m.summary.rootMeanSquaredError:.3f}")
rows.append(rmse_row)
# Build header: first column "Predictor", then for each model: "y: [outcome] ([name])"
header = ["Predictor"]
for out, name in zip(outcomes, names):
header.append(f"y: {out} ({name})")
# Create table string using grid format.
table_str = tabulate(rows, headers=header, tablefmt="grid", colalign=("left",) + ("right",)*len(models))
# Split into lines.
lines = table_str.split("\n")
# Create a dashed line spanning the full width.
full_width = len(lines[0])
dash_line = '-' * full_width
# Create an equals line by replacing '-' with '='.
eq_line = dash_line.replace('-', '=')
# Insert a dashed line after the header row.
lines = table_str.split("\n")
# In grid format, header and separator are usually the first two lines.
lines.insert(2, dash_line)
# Insert an equals line after the Intercept row.
for i, line in enumerate(lines):
if line.startswith("|") and "Intercept" in line:
if i+1 < len(lines):
lines[i+1] = eq_line
break
# Add dashed lines at the very top and bottom.
final_table = dash_line + "\n" + "\n".join(lines) + "\n" + dash_line
return final_table
# Example usage:
# print(compare_reg_models([model_1, model_2, model_3],
# [assembler_1, assembler_2, assembler_3],
# ["Model 1", "Model 2", "Model 3"]))compare_rmse
def compare_rmse(test_dfs, label_col, pred_col="prediction", names=None):
"""
Computes and compares RMSE values for a list of test DataFrames.
For each DataFrame in test_dfs, this function calculates the RMSE between the actual outcome
(given by label_col) and the predicted value (given by pred_col, default "prediction"). It then
produces a formatted table where the first column header is empty and the first row's first cell is
"RMSE", with each model's RMSE in its own column.
Parameters:
test_dfs (list): List of test DataFrames.
label_col (str): The name of the outcome column.
pred_col (str, optional): The name of the prediction column (default "prediction").
names (list, optional): List of model names corresponding to the test DataFrames.
Defaults to "Model 1", "Model 2", etc.
Returns:
A formatted string containing a table that compares RMSE values for each test DataFrame,
with one model per column.
"""
# Set default model names if none provided.
if names is None:
names = [f"Model {i+1}" for i in range(len(test_dfs))]
rmse_values = []
for df in test_dfs:
# Create a column for squared error.
df = df.withColumn("error_sq", pow(col(label_col) - col(pred_col), 2))
# Calculate RMSE: square root of the mean squared error.
rmse = df.agg(sqrt(avg("error_sq")).alias("rmse")).collect()[0]["rmse"]
rmse_values.append(rmse)
# Build a single row table: first cell "RMSE", then one cell per model with the RMSE value.
row = ["RMSE"] + [f"{rmse:.3f}" for rmse in rmse_values]
# Build header: first column header is empty, then model names.
header = [""] + names
table_str = tabulate([row], headers=header, tablefmt="grid", colalign=("left",) + ("right",)*len(names))
return table_str
# Example usage:
# print(compare_rmse([dtest_1, dtest_2, dtest_3], "log_sales", names=["Model 1", "Model 2", "Model 3"]))residual_plot
def residual_plot(df, label_col, model_name):
"""
Generates a residual plot for a given test dataframe.
Parameters:
df (DataFrame): Spark DataFrame containing the test set with predictions.
label_col (str): The column name of the actual outcome variable.
title (str): The title for the residual plot.
Returns:
None (displays the plot)
"""
# Convert to Pandas DataFrame
df_pd = df.select(["prediction", label_col]).toPandas()
df_pd["residual"] = df_pd[label_col] - df_pd["prediction"]
# Scatter plot of residuals vs. predicted values
plt.scatter(df_pd["prediction"], df_pd["residual"], alpha=0.2, color="darkgray")
# Use LOWESS smoothing for trend line
smoothed = sm.nonparametric.lowess(df_pd["residual"], df_pd["prediction"])
plt.plot(smoothed[:, 0], smoothed[:, 1], color="darkblue")
# Add reference line at y=0
plt.axhline(y=0, color="red", linestyle="--")
# Labels and title (model_name)
plt.xlabel("Predicted Values")
plt.ylabel("Residuals")
model_name = "Residual Plot for " + model_name
plt.title(model_name)
# Show plot
plt.show()
# Example usage:
# residual_plot(dtest_1, "log_sales", "Model 1")Loading DataFrame - Homes
homes = pd.read_csv(
'https://bcdanl.github.io/data/american_housing_survey.csv'
)
homes.head()Warning: Total number of columns (29) exceeds max_columns (20). Falling back to pandas display.| LPRICE | VALUE | STATE | METRO | ZINC2 | HHGRAD | BATHS | BEDRMS | PER | ZADULT | ... | EABAN | HOWH | HOWN | ODORA | STRNA | AMMORT | INTW | MATBUY | DWNPAY | FRSTHO | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 85000 | 150000 | GA | rural | 15600 | No HS | 2 | 3 | 1 | 1 | ... | 0 | good | good | 0 | 0 | 50000 | 9 | 1 | other | 0 |
| 1 | 76500 | 130000 | GA | rural | 61001 | HS Grad | 2 | 3 | 5 | 2 | ... | 0 | good | bad | 0 | 1 | 70000 | 5 | 1 | other | 1 |
| 2 | 93900 | 135000 | GA | rural | 38700 | HS Grad | 2 | 3 | 4 | 2 | ... | 0 | good | good | 0 | 0 | 117000 | 6 | 0 | other | 1 |
| 3 | 100000 | 140000 | GA | rural | 80000 | No HS | 3 | 4 | 2 | 2 | ... | 0 | good | good | 0 | 1 | 100000 | 7 | 1 | prev home | 0 |
| 4 | 100000 | 135000 | GA | rural | 61000 | HS Grad | 2 | 3 | 2 | 2 | ... | 0 | good | good | 0 | 0 | 100000 | 4 | 1 | other | 1 |
5 rows × 29 columns
Exploratory Data Analysis
Before applying our Logistic Regression Model, let’s explore some of the relationships in this DataFrame.
Home Value vs Household Income
homes['log_income'] = np.log(homes['ZINC2'])
homes['log_value'] = np.log(homes['VALUE'])/usr/local/lib/python3.11/dist-packages/pandas/core/arraylike.py:399: RuntimeWarning: divide by zero encountered in log
result = getattr(ufunc, method)(*inputs, **kwargs)
/usr/local/lib/python3.11/dist-packages/pandas/core/arraylike.py:399: RuntimeWarning: invalid value encountered in log
result = getattr(ufunc, method)(*inputs, **kwargs)sns.scatterplot(x=homes['log_income'], y=homes['log_value'], alpha=0.3)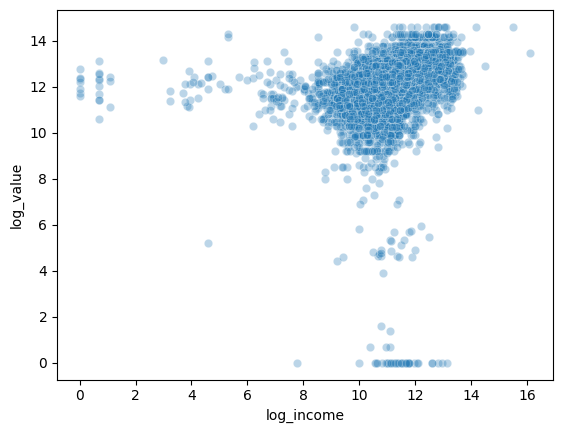
This scatterplot shows the relationship between the log of household income and the log of home values. I took the log of each variable to reduce skewness and make it easier to see patterns in the scatterplot. Here, we can see that a higher household income is generally associated with a higher house value.
Number of Bedrooms vs House Value
sns.boxplot(x=homes['BEDRMS'], y=homes['VALUE'])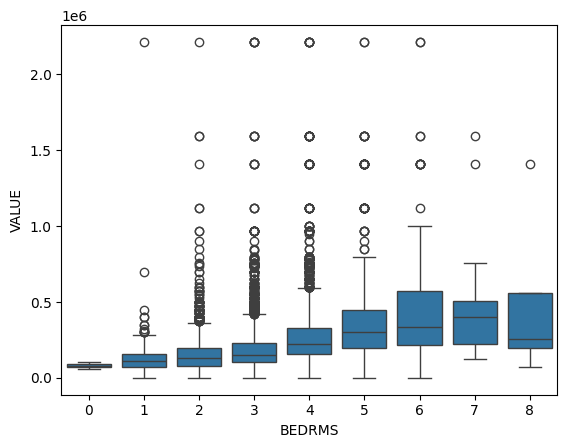
These boxplots show the distribution of house values for different numbers of bedrooms. Houses with 6 and 8 bedrooms have the widest range in house value, whereas houses with only 1 bedroom have the least amount of variation in value. Houses with more bedrooms may have greater variation in value because they could range from older, lower value properties to newer, high value estates. Overall, as more bedrooms are added, home values tend to increase but with greater variability.
Junk in the Streets vs House Value
sns.boxplot(x=homes['EJUNK'], y=homes['VALUE'])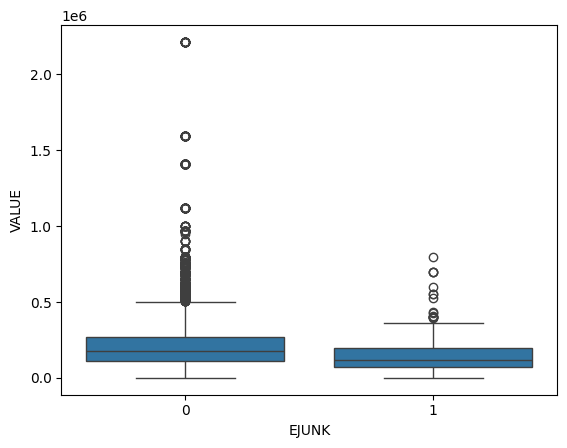
These boxplots show the distribution of house values for the amount of junk in the streets. Houses without junk in the streets have a slightly wider range of values than houses with junk in the streets. Additionally, houses with junk in the streets tend to be slightly less expensive than houses without junk in the streets.
Linear Regression
Next, we will build a Linear Regression Model to predict home values based on several variables and analyze the accurary of its predictions. For the predictor variables, we will use all of the variables in the DataFrame, excluding home value, the amount of the first mortgage payment, and the purchase price of the unit and land. The outcome variable will be the log value of the home.
Log Transformation
df = spark.createDataFrame(homes)
df = (
df
.withColumn("LOG_VALUE",
log(df['VALUE']) )
)Training-Test Split
dtrain, dtest = df.randomSplit([0.6, 0.4], seed = 1234)Assigning Dummy Variables
Before we begin training our models, we must add dummy variables for our categorical variables. To do this, we will apply our UDF for adding dummy variables. All observations must be numerical in order to train the Linear Regression Model.
dummy_cols_STATE, ref_category_STATE = add_dummy_variables('STATE', 0)
dummy_cols_METRO, ref_category_METRO = add_dummy_variables('METRO', 0)
dummy_cols_HHGRAD, ref_category_HHGRAD = add_dummy_variables('HHGRAD', 1)
dummy_cols_HOWH, ref_category_HOWH = add_dummy_variables('HOWH', 0)
dummy_cols_HOWN, ref_category_HOWN = add_dummy_variables('HOWN', 0)
dummy_cols_DWNPAY, ref_category_DWNPAY = add_dummy_variables('DWNPAY', 0)Reference category (dummy omitted): CA
Reference category (dummy omitted): rural
Reference category (dummy omitted): Bach
Reference category (dummy omitted): bad
Reference category (dummy omitted): bad
Reference category (dummy omitted): otherLinear Regression (Model 1)
# assembling predictors
conti_cols = ['ZINC2', 'BATHS', 'BEDRMS', 'PER', 'ZADULT', 'NUNITS', 'EAPTBL', 'ECOM1', 'ECOM2', 'EGREEN', 'EJUNK', 'ELOW1',
'ESFD', 'ETRANS', 'EABAN', 'ODORA', 'STRNA', 'INTW', 'MATBUY', 'FRSTHO']
dummy_cols = dummy_cols_STATE + dummy_cols_METRO + dummy_cols_HHGRAD + dummy_cols_HOWH + dummy_cols_HOWN + dummy_cols_DWNPAY
assembler_predictors_1 = (
conti_cols +
dummy_cols
)
assembler_1 = VectorAssembler(
inputCols = assembler_predictors_1,
outputCol = "predictors"
)
dtrain_1 = assembler_1.transform(dtrain)
dtest_1 = assembler_1.transform(dtest)
# training model
model_1 = (
LinearRegression(featuresCol="predictors",
labelCol="LOG_VALUE")
.fit(dtrain_1)
)
# making prediction
dtest_1 = model_1.transform(dtest_1)
# makting regression table
print( regression_table(model_1, assembler_1) )+------------------+--------+-----------+------+------------+---------+--------------+--------------+-------------------+-------------------+
| y: LOG_VALUE | Beta | Exp(Beta) | Sig. | Std. Error | p-value | 95% CI Lower | 95% CI Upper | Exp(95% CI Lower) | Exp(95% CI Upper) |
+------------------+--------+-----------+------+------------+---------+--------------+--------------+-------------------+-------------------+
| ZINC2 | 0.000 | 1.000 | *** | 0.014 | 0.000 | -0.028 | 0.028 | 0.972 | 1.029 |
| BATHS | 0.211 | 1.235 | *** | 0.013 | 0.000 | 0.186 | 0.236 | 1.205 | 1.266 |
| BEDRMS | 0.089 | 1.093 | *** | 0.008 | 0.000 | 0.074 | 0.105 | 1.077 | 1.110 |
| PER | 0.005 | 1.005 | | 0.014 | 0.533 | -0.022 | 0.032 | 0.978 | 1.032 |
| ZADULT | -0.022 | 0.978 | | 0.001 | 0.106 | -0.023 | -0.021 | 0.977 | 0.979 |
| NUNITS | -0.001 | 0.999 | ** | 0.030 | 0.016 | -0.060 | 0.057 | 0.942 | 1.058 |
| EAPTBL | -0.020 | 0.980 | | 0.024 | 0.491 | -0.068 | 0.027 | 0.934 | 1.028 |
| ECOM1 | -0.006 | 0.994 | | 0.062 | 0.818 | -0.126 | 0.115 | 0.881 | 1.122 |
| ECOM2 | -0.067 | 0.935 | | 0.018 | 0.274 | -0.102 | -0.033 | 0.903 | 0.968 |
| EGREEN | 0.006 | 1.006 | | 0.065 | 0.717 | -0.121 | 0.134 | 0.886 | 1.143 |
| EJUNK | -0.215 | 0.807 | *** | 0.029 | 0.001 | -0.272 | -0.158 | 0.762 | 0.854 |
| ELOW1 | 0.022 | 1.022 | | 0.037 | 0.445 | -0.050 | 0.094 | 0.951 | 1.099 |
| ESFD | 0.279 | 1.322 | *** | 0.033 | 0.000 | 0.215 | 0.343 | 1.240 | 1.409 |
| ETRANS | -0.075 | 0.928 | ** | 0.046 | 0.022 | -0.165 | 0.015 | 0.848 | 1.015 |
| EABAN | -0.178 | 0.837 | *** | 0.041 | 0.000 | -0.260 | -0.097 | 0.771 | 0.907 |
| ODORA | -0.010 | 0.990 | | 0.020 | 0.811 | -0.049 | 0.030 | 0.952 | 1.030 |
| STRNA | -0.028 | 0.972 | | 0.006 | 0.162 | -0.039 | -0.017 | 0.962 | 0.983 |
| INTW | -0.048 | 0.953 | *** | 0.017 | 0.000 | -0.082 | -0.014 | 0.922 | 0.986 |
| MATBUY | -0.017 | 0.983 | | 0.022 | 0.319 | -0.060 | 0.025 | 0.942 | 1.026 |
| FRSTHO | -0.083 | 0.920 | *** | 0.037 | 0.000 | -0.155 | -0.011 | 0.856 | 0.989 |
| STATE_CO | -0.294 | 0.745 | *** | 0.039 | 0.000 | -0.371 | -0.218 | 0.690 | 0.804 |
| STATE_CT | -0.327 | 0.721 | *** | 0.039 | 0.000 | -0.403 | -0.251 | 0.668 | 0.778 |
| STATE_GA | -0.615 | 0.540 | *** | 0.071 | 0.000 | -0.754 | -0.477 | 0.470 | 0.621 |
| STATE_IL | -0.862 | 0.422 | *** | 0.038 | 0.000 | -0.937 | -0.787 | 0.392 | 0.455 |
| STATE_IN | -0.736 | 0.479 | *** | 0.046 | 0.000 | -0.828 | -0.645 | 0.437 | 0.524 |
| STATE_LA | -0.712 | 0.490 | *** | 0.043 | 0.000 | -0.796 | -0.629 | 0.451 | 0.533 |
| STATE_MO | -0.645 | 0.525 | *** | 0.041 | 0.000 | -0.725 | -0.565 | 0.484 | 0.569 |
| STATE_OH | -0.636 | 0.529 | *** | 0.041 | 0.000 | -0.717 | -0.556 | 0.488 | 0.573 |
| STATE_OK | -0.996 | 0.369 | *** | 0.043 | 0.000 | -1.080 | -0.913 | 0.340 | 0.401 |
| STATE_PA | -0.891 | 0.410 | *** | 0.043 | 0.000 | -0.975 | -0.806 | 0.377 | 0.447 |
| STATE_TX | -1.045 | 0.352 | *** | 0.039 | 0.000 | -1.120 | -0.969 | 0.326 | 0.379 |
| STATE_WA | -0.089 | 0.915 | ** | 0.023 | 0.022 | -0.133 | -0.044 | 0.875 | 0.957 |
| METRO_urban | 0.092 | 1.096 | *** | 0.029 | 0.000 | 0.034 | 0.149 | 1.035 | 1.160 |
| HHGRAD_Assoc | -0.153 | 0.858 | *** | 0.026 | 0.000 | -0.205 | -0.102 | 0.815 | 0.903 |
| HHGRAD_Grad | 0.079 | 1.083 | *** | 0.021 | 0.003 | 0.038 | 0.121 | 1.039 | 1.128 |
| HHGRAD_HS_Grad | -0.178 | 0.837 | *** | 0.037 | 0.000 | -0.251 | -0.106 | 0.778 | 0.899 |
| HHGRAD_No_HS | -0.321 | 0.725 | *** | 0.033 | 0.000 | -0.386 | -0.257 | 0.680 | 0.774 |
| HOWH_good | 0.180 | 1.197 | *** | 0.027 | 0.000 | 0.126 | 0.233 | 1.134 | 1.263 |
| HOWN_good | 0.111 | 1.118 | *** | 0.022 | 0.000 | 0.067 | 0.155 | 1.070 | 1.168 |
| DWNPAY_prev_home | 0.133 | 1.142 | *** | 0.076 | 0.000 | -0.017 | 0.283 | 0.983 | 1.326 |
| Intercept | 11.708 | | *** | 0.000 | | 11.708 | | 11.708 | |
---------------------------------------------------------------------------------------------------------------------------------------------
| Observations | 9,351 | | | | | | | | |
| R² | 0.318 | | | | | | | | |
| RMSE | 0.793 | | | | | | | | |
+------------------+--------+-----------+------+------------+---------+--------------+--------------+-------------------+-------------------+Each predictor variable’s statistical significance is rated by stars under the column “Sig.”. Predictors that are not statisically significant do not have any stars. We can see in the regression table that not all of the predictor variables are statistically significant. In our next Linear Regression Model, we will only include variables that are statistically significant. We can then compare the two models and decide whether or not removing non-statistically significant variables impacts the accuracy of the model and functionality of the model.
New Linear Regression (Model 2)
# assembling predictors
conti_cols_2 = ['ZINC2', 'BATHS', 'BEDRMS', 'NUNITS', 'EJUNK',
'ESFD', 'ETRANS', 'EABAN', 'INTW', 'FRSTHO']
dummy_cols = dummy_cols_STATE + dummy_cols_METRO + dummy_cols_HHGRAD + dummy_cols_HOWH + dummy_cols_HOWN + dummy_cols_DWNPAY
assembler_predictors_2 = (
conti_cols_2 +
dummy_cols
)
assembler_2 = VectorAssembler(
inputCols = assembler_predictors_2,
outputCol = "predictors"
)
dtrain_2 = assembler_2.transform(dtrain)
dtest_2 = assembler_2.transform(dtest)
# training model
model_2 = (
LinearRegression(featuresCol="predictors",
labelCol="LOG_VALUE")
.fit(dtrain_2)
)
# making prediction
dtest_2 = model_2.transform(dtest_2)
# makting regression table
print( regression_table(model_2, assembler_2) )+------------------+--------+-----------+------+------------+---------+--------------+--------------+-------------------+-------------------+
| y: LOG_VALUE | Beta | Exp(Beta) | Sig. | Std. Error | p-value | 95% CI Lower | 95% CI Upper | Exp(95% CI Lower) | Exp(95% CI Upper) |
+------------------+--------+-----------+------+------------+---------+--------------+--------------+-------------------+-------------------+
| ZINC2 | 0.000 | 1.000 | *** | 0.014 | 0.000 | -0.028 | 0.028 | 0.972 | 1.028 |
| BATHS | 0.213 | 1.238 | *** | 0.012 | 0.000 | 0.190 | 0.236 | 1.210 | 1.267 |
| BEDRMS | 0.087 | 1.091 | *** | 0.001 | 0.000 | 0.086 | 0.088 | 1.089 | 1.092 |
| NUNITS | -0.002 | 0.998 | ** | 0.065 | 0.011 | -0.129 | 0.126 | 0.879 | 1.134 |
| EJUNK | -0.219 | 0.803 | *** | 0.036 | 0.001 | -0.290 | -0.148 | 0.748 | 0.862 |
| ESFD | 0.273 | 1.315 | *** | 0.032 | 0.000 | 0.211 | 0.336 | 1.235 | 1.399 |
| ETRANS | -0.088 | 0.916 | *** | 0.045 | 0.006 | -0.177 | 0.001 | 0.838 | 1.001 |
| EABAN | -0.188 | 0.829 | *** | 0.005 | 0.000 | -0.198 | -0.177 | 0.820 | 0.838 |
| INTW | -0.049 | 0.952 | *** | 0.022 | 0.000 | -0.092 | -0.007 | 0.912 | 0.993 |
| FRSTHO | -0.084 | 0.919 | *** | 0.037 | 0.000 | -0.156 | -0.013 | 0.856 | 0.988 |
| STATE_CO | -0.290 | 0.748 | *** | 0.039 | 0.000 | -0.366 | -0.213 | 0.693 | 0.808 |
| STATE_CT | -0.328 | 0.720 | *** | 0.038 | 0.000 | -0.403 | -0.253 | 0.668 | 0.777 |
| STATE_GA | -0.615 | 0.541 | *** | 0.071 | 0.000 | -0.754 | -0.477 | 0.471 | 0.621 |
| STATE_IL | -0.867 | 0.420 | *** | 0.038 | 0.000 | -0.942 | -0.793 | 0.390 | 0.453 |
| STATE_IN | -0.736 | 0.479 | *** | 0.046 | 0.000 | -0.826 | -0.645 | 0.438 | 0.525 |
| STATE_LA | -0.716 | 0.489 | *** | 0.043 | 0.000 | -0.799 | -0.633 | 0.450 | 0.531 |
| STATE_MO | -0.645 | 0.525 | *** | 0.041 | 0.000 | -0.724 | -0.565 | 0.485 | 0.568 |
| STATE_OH | -0.640 | 0.527 | *** | 0.041 | 0.000 | -0.720 | -0.561 | 0.487 | 0.571 |
| STATE_OK | -0.997 | 0.369 | *** | 0.042 | 0.000 | -1.081 | -0.914 | 0.339 | 0.401 |
| STATE_PA | -0.892 | 0.410 | *** | 0.043 | 0.000 | -0.976 | -0.808 | 0.377 | 0.446 |
| STATE_TX | -1.047 | 0.351 | *** | 0.039 | 0.000 | -1.122 | -0.971 | 0.326 | 0.379 |
| STATE_WA | -0.089 | 0.915 | ** | 0.022 | 0.021 | -0.133 | -0.045 | 0.876 | 0.956 |
| METRO_urban | 0.087 | 1.090 | *** | 0.029 | 0.000 | 0.030 | 0.144 | 1.030 | 1.154 |
| HHGRAD_Assoc | -0.157 | 0.855 | *** | 0.026 | 0.000 | -0.208 | -0.105 | 0.812 | 0.900 |
| HHGRAD_Grad | 0.080 | 1.083 | *** | 0.021 | 0.003 | 0.039 | 0.121 | 1.039 | 1.128 |
| HHGRAD_HS_Grad | -0.183 | 0.833 | *** | 0.037 | 0.000 | -0.255 | -0.111 | 0.775 | 0.895 |
| HHGRAD_No_HS | -0.329 | 0.719 | *** | 0.033 | 0.000 | -0.394 | -0.265 | 0.675 | 0.767 |
| HOWH_good | 0.180 | 1.197 | *** | 0.027 | 0.000 | 0.127 | 0.233 | 1.136 | 1.262 |
| HOWN_good | 0.119 | 1.126 | *** | 0.022 | 0.000 | 0.075 | 0.163 | 1.078 | 1.177 |
| DWNPAY_prev_home | 0.133 | 1.143 | *** | 0.073 | 0.000 | -0.009 | 0.276 | 0.991 | 1.318 |
| Intercept | 11.677 | | *** | 0.000 | | 11.677 | | 11.677 | |
---------------------------------------------------------------------------------------------------------------------------------------------
| Observations | 9,351 | | | | | | | | |
| R² | 0.318 | | | | | | | | |
| RMSE | 0.794 | | | | | | | | |
+------------------+--------+-----------+------+------------+---------+--------------+--------------+-------------------+-------------------+Model Comparison
We can compare the models by looking for differences in their beta, \(R^2\), and RMSE values, as well as their residual plots.
Beta and \(R^2\) values
print(compare_reg_models([model_1, model_2],
[assembler_1, assembler_2],
["Model 1", "Model 2"]))--------------------------------------------------------------------------
+------------------+--------------------------+--------------------------+
| Predictor | y: LOG_VALUE (Model 1) | y: LOG_VALUE (Model 2) |
--------------------------------------------------------------------------
+==================+==========================+==========================+
| ZINC2 | 0.000*** / 1.000 | 0.000*** / 1.000 |
+------------------+--------------------------+--------------------------+
| BATHS | 0.211*** / 1.235 | 0.213*** / 1.238 |
+------------------+--------------------------+--------------------------+
| BEDRMS | 0.089*** / 1.093 | 0.087*** / 1.091 |
+------------------+--------------------------+--------------------------+
| PER | 0.005 / 1.005 | |
+------------------+--------------------------+--------------------------+
| ZADULT | -0.022 / 0.978 | |
+------------------+--------------------------+--------------------------+
| NUNITS | -0.001** / 0.999 | -0.002** / 0.998 |
+------------------+--------------------------+--------------------------+
| EAPTBL | -0.020 / 0.980 | |
+------------------+--------------------------+--------------------------+
| ECOM1 | -0.006 / 0.994 | |
+------------------+--------------------------+--------------------------+
| ECOM2 | -0.067 / 0.935 | |
+------------------+--------------------------+--------------------------+
| EGREEN | 0.006 / 1.006 | |
+------------------+--------------------------+--------------------------+
| EJUNK | -0.215*** / 0.807 | -0.219*** / 0.803 |
+------------------+--------------------------+--------------------------+
| ELOW1 | 0.022 / 1.022 | |
+------------------+--------------------------+--------------------------+
| ESFD | 0.279*** / 1.322 | 0.273*** / 1.315 |
+------------------+--------------------------+--------------------------+
| ETRANS | -0.075** / 0.928 | -0.088*** / 0.916 |
+------------------+--------------------------+--------------------------+
| EABAN | -0.178*** / 0.837 | -0.188*** / 0.829 |
+------------------+--------------------------+--------------------------+
| ODORA | -0.010 / 0.990 | |
+------------------+--------------------------+--------------------------+
| STRNA | -0.028 / 0.972 | |
+------------------+--------------------------+--------------------------+
| INTW | -0.048*** / 0.953 | -0.049*** / 0.952 |
+------------------+--------------------------+--------------------------+
| MATBUY | -0.017 / 0.983 | |
+------------------+--------------------------+--------------------------+
| FRSTHO | -0.083*** / 0.920 | -0.084*** / 0.919 |
+------------------+--------------------------+--------------------------+
| STATE_CO | -0.294*** / 0.745 | -0.290*** / 0.748 |
+------------------+--------------------------+--------------------------+
| STATE_CT | -0.327*** / 0.721 | -0.328*** / 0.720 |
+------------------+--------------------------+--------------------------+
| STATE_GA | -0.615*** / 0.540 | -0.615*** / 0.541 |
+------------------+--------------------------+--------------------------+
| STATE_IL | -0.862*** / 0.422 | -0.867*** / 0.420 |
+------------------+--------------------------+--------------------------+
| STATE_IN | -0.736*** / 0.479 | -0.736*** / 0.479 |
+------------------+--------------------------+--------------------------+
| STATE_LA | -0.712*** / 0.490 | -0.716*** / 0.489 |
+------------------+--------------------------+--------------------------+
| STATE_MO | -0.645*** / 0.525 | -0.645*** / 0.525 |
+------------------+--------------------------+--------------------------+
| STATE_OH | -0.636*** / 0.529 | -0.640*** / 0.527 |
+------------------+--------------------------+--------------------------+
| STATE_OK | -0.996*** / 0.369 | -0.997*** / 0.369 |
+------------------+--------------------------+--------------------------+
| STATE_PA | -0.891*** / 0.410 | -0.892*** / 0.410 |
+------------------+--------------------------+--------------------------+
| STATE_TX | -1.045*** / 0.352 | -1.047*** / 0.351 |
+------------------+--------------------------+--------------------------+
| STATE_WA | -0.089** / 0.915 | -0.089** / 0.915 |
+------------------+--------------------------+--------------------------+
| METRO_urban | 0.092*** / 1.096 | 0.087*** / 1.090 |
+------------------+--------------------------+--------------------------+
| HHGRAD_Assoc | -0.153*** / 0.858 | -0.157*** / 0.855 |
+------------------+--------------------------+--------------------------+
| HHGRAD_Grad | 0.079*** / 1.083 | 0.080*** / 1.083 |
+------------------+--------------------------+--------------------------+
| HHGRAD_HS_Grad | -0.178*** / 0.837 | -0.183*** / 0.833 |
+------------------+--------------------------+--------------------------+
| HHGRAD_No_HS | -0.321*** / 0.725 | -0.329*** / 0.719 |
+------------------+--------------------------+--------------------------+
| HOWH_good | 0.180*** / 1.197 | 0.180*** / 1.197 |
+------------------+--------------------------+--------------------------+
| HOWN_good | 0.111*** / 1.118 | 0.119*** / 1.126 |
+------------------+--------------------------+--------------------------+
| DWNPAY_prev_home | 0.133*** / 1.142 | 0.133*** / 1.143 |
+------------------+--------------------------+--------------------------+
| Intercept | 11.708*** | 11.677*** |
==========================================================================
| Observations | 9,351 | 9,351 |
+------------------+--------------------------+--------------------------+
| R² | 0.318 | 0.318 |
+------------------+--------------------------+--------------------------+
| RMSE | 0.793 | 0.794 |
+------------------+--------------------------+--------------------------+
--------------------------------------------------------------------------The two models generally have similar or the same beta values for each predictor. They also have the same \(R^2\) values. This suggests that one of the models may not be more accurate in predicting house value than the other and that the two are functionally equivalent.
RMSE
print(compare_rmse([dtest_1, dtest_2], "LOG_VALUE"))+------+-----------+-----------+
| | Model 1 | Model 2 |
+======+===========+===========+
| RMSE | 0.851 | 0.852 |
+------+-----------+-----------+The RMSE values for the two models are relatively the same, with Model 1 having a slightly lower value. This suggests that Model 1 may be a slightly better fit for the data.
Residual Plots
residual_plot(dtest_1, "LOG_VALUE", "Model 1")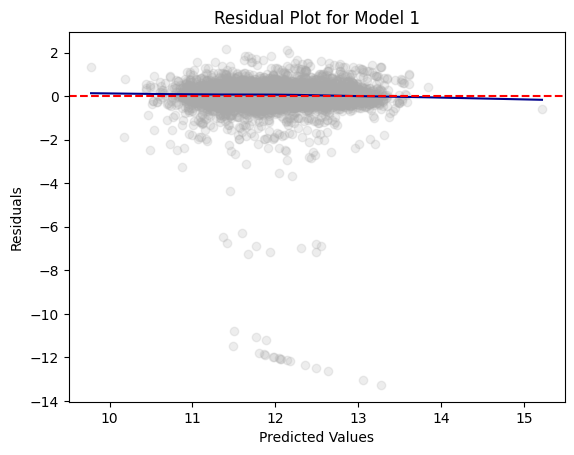
residual_plot(dtest_2, "LOG_VALUE", "Model 2")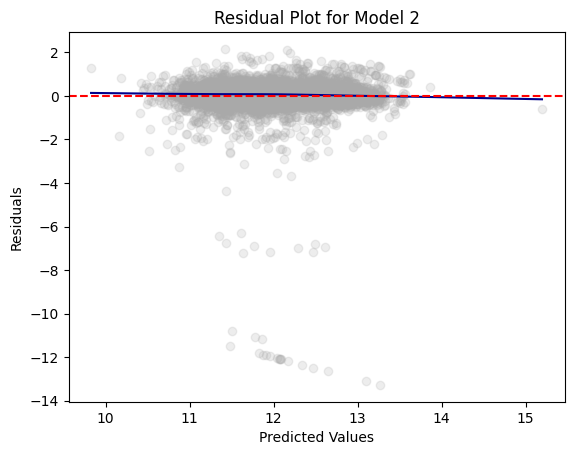
The residual plots for Model 1 and Model 2 look relatively the same. This shows us that the models are able to predict the home value with the same or similar accuracy.
Overall, the residual plots, beta values, \(R^2\) values, and RMSE values were relatively the same for both models. This proves that the variables removed in Model 2 were in fact not statistically significant. Their removal did not have a major impact on the Linear Regression model.
Logistic Regression
Next, we will build a Logistic Regression Model using the same DataFrame, homes. However, this time we will have the model predict whether the buyer made a down payment of 20% or more. This outcome variable will be a new variable named “GT20DOWN”. Our predictor variables will once again be all available variables, excluding the amount of the first mortgage and the purchase price of the unit and land.
Outcome Variable
df = df.withColumn("GT20DOWN", when((col("LPRICE") - col("AMMORT")) / col("LPRICE") > 0, 1).otherwise(0))Split into Training/Testing
dtrain, dtest = df.randomSplit([0.6, 0.4], seed=1234)Dummy Variables
dummy_cols_STATE, ref_category_STATE = add_dummy_variables('STATE', 0)
dummy_cols_METRO, ref_category_METRO = add_dummy_variables('METRO', 0)
dummy_cols_HHGRAD, ref_category_HHGRAD = add_dummy_variables('HHGRAD', 1)
dummy_cols_HOWH, ref_category_HOWH = add_dummy_variables('HOWH', 0)
dummy_cols_HOWN, ref_category_HOWN = add_dummy_variables('HOWN', 0)
dummy_cols_DWNPAY, ref_category_DWNPAY = add_dummy_variables('DWNPAY', 0)Reference category (dummy omitted): CA
Reference category (dummy omitted): rural
Reference category (dummy omitted): Bach
Reference category (dummy omitted): bad
Reference category (dummy omitted): bad
Reference category (dummy omitted): other
# Keep the name assembler_predictors unchanged,
# as it will be used as a global variable in the marginal_effects UDF.
assembler_predictors = (
conti_cols_2 +
dummy_cols
)
assembler_3 = VectorAssembler(
inputCols = assembler_predictors,
outputCol = "predictors"
)
dtrain_3 = assembler_3.transform(dtrain)
dtest_3 = assembler_3.transform(dtest)# training the model
model_3 = (
GeneralizedLinearRegression(featuresCol="predictors",
labelCol="GT20DOWN",
family="binomial",
link="logit")
.fit(dtrain_3)
)dtrain_3 = model_3.transform(dtrain_3)
dtest_3 = model_3.transform(dtest_3)model_3.summaryCoefficients:
Feature Estimate Std Error T Value P Value
(Intercept) 0.7348 0.1998 3.6781 0.0002
ZINC2 0.0000 0.0000 0.8766 0.3807
BATHS 0.2872 0.0407 7.0522 0.0000
BEDRMS -0.0784 0.0323 -2.4263 0.0153
NUNITS 0.0129 0.0061 2.1077 0.0351
EJUNK -0.2353 0.1723 -1.3658 0.1720
ESFD -0.2221 0.0997 -2.2287 0.0258
ETRANS -0.1349 0.0844 -1.5981 0.1100
EABAN -0.3862 0.1205 -3.2045 0.0014
INTW -0.0686 0.0148 -4.6394 0.0000
FRSTHO -0.3151 0.0568 -5.5470 0.0000
STATE_CO -0.1912 0.0984 -1.9438 0.0519
STATE_CT 0.7224 0.1092 6.6139 0.0000
STATE_GA 0.0132 0.1038 0.1277 0.8984
STATE_IL 0.3506 0.1939 1.8087 0.0705
STATE_IN 0.2030 0.1031 1.9687 0.0490
STATE_LA 0.4599 0.1255 3.6651 0.0002
STATE_MO 0.2093 0.1154 1.8130 0.0698
STATE_OH 0.5330 0.1115 4.7800 0.0000
STATE_OK 0.0986 0.1092 0.9034 0.3663
STATE_PA 0.2630 0.1146 2.2937 0.0218
STATE_TX 0.1307 0.1147 1.1400 0.2543
STATE_WA 0.1071 0.1041 1.0287 0.3036
METRO_urban 0.0673 0.0603 1.1174 0.2638
HHGRAD_Assoc -0.6806 0.0783 -8.6891 0.0000
HHGRAD_Grad -0.0532 0.0764 -0.6958 0.4865
HHGRAD_HS_Grad -0.6810 0.0579 -11.7598 0.0000
HHGRAD_No_HS -0.8795 0.0977 -9.0009 0.0000
HOWH_good 0.0314 0.0871 0.3603 0.7186
HOWN_good 0.2052 0.0715 2.8701 0.0041
DWNPAY_prev_home 0.6042 0.0620 9.7496 0.0000
(Dispersion parameter for binomial family taken to be 1.0000)
Null deviance: 12511.4865 on 9320 degrees of freedom
Residual deviance: 11489.7938 on 9320 degrees of freedom
AIC: 11551.7938Marginal Effects
We can use the marginal effect of a predictor variable to analyze the relationship or association between the predictor and outcome variable. In this case, we will interpret the association between first-time homeownership and the probability of making a 20%+ down payment. Additionally, we will be able to interpret the association between number of bedrooms in the home and the probability of making a 20%+ down payment.
# Compute means
means_df = dtrain_3.select([mean(col).alias(col) for col in assembler_predictors])
# Collect the results as a list
means = means_df.collect()[0]
means_list = [means[col] for col in assembler_predictors]table_output, df_ME = marginal_effects(model_3, means_list)
print(table_output)+------------------+-----------------+--------------+------------+--------------+--------------+
| Variable | Marginal Effect | Significance | Std. Error | 95% CI Lower | 95% CI Upper |
+------------------+-----------------+--------------+------------+--------------+--------------+
| ZINC2 | 0.0000 | | 0.0000 | -0.0000 | 0.0000 |
| BATHS | 0.0674 | *** | 0.0096 | 0.0487 | 0.0861 |
| BEDRMS | -0.0184 | ** | 0.0076 | -0.0333 | -0.0035 |
| NUNITS | 0.0030 | ** | 0.0014 | 0.0002 | 0.0058 |
| EJUNK | -0.0552 | | 0.0404 | -0.1345 | 0.0240 |
| ESFD | -0.0521 | ** | 0.0234 | -0.0980 | -0.0063 |
| ETRANS | -0.0316 | | 0.0198 | -0.0705 | 0.0072 |
| EABAN | -0.0906 | *** | 0.0283 | -0.1461 | -0.0352 |
| INTW | -0.0161 | *** | 0.0035 | -0.0229 | -0.0093 |
| FRSTHO | -0.0739 | *** | 0.0133 | -0.1001 | -0.0478 |
| STATE_CO | -0.0449 | * | 0.0231 | -0.0901 | 0.0004 |
| STATE_CT | 0.1695 | *** | 0.0256 | 0.1193 | 0.2198 |
| STATE_GA | 0.0031 | | 0.0244 | -0.0446 | 0.0508 |
| STATE_IL | 0.0823 | * | 0.0455 | -0.0069 | 0.1714 |
| STATE_IN | 0.0476 | ** | 0.0242 | 0.0002 | 0.0951 |
| STATE_LA | 0.1079 | *** | 0.0294 | 0.0502 | 0.1656 |
| STATE_MO | 0.0491 | * | 0.0271 | -0.0040 | 0.1022 |
| STATE_OH | 0.1251 | *** | 0.0262 | 0.0738 | 0.1764 |
| STATE_OK | 0.0231 | | 0.0256 | -0.0271 | 0.0734 |
| STATE_PA | 0.0617 | ** | 0.0269 | 0.0090 | 0.1144 |
| STATE_TX | 0.0307 | | 0.0269 | -0.0221 | 0.0834 |
| STATE_WA | 0.0251 | | 0.0244 | -0.0228 | 0.0730 |
| METRO_urban | 0.0158 | | 0.0141 | -0.0119 | 0.0435 |
| HHGRAD_Assoc | -0.1597 | *** | 0.0184 | -0.1957 | -0.1237 |
| HHGRAD_Grad | -0.0125 | | 0.0179 | -0.0476 | 0.0227 |
| HHGRAD_HS_Grad | -0.1598 | *** | 0.0136 | -0.1864 | -0.1332 |
| HHGRAD_No_HS | -0.2064 | *** | 0.0229 | -0.2513 | -0.1614 |
| HOWH_good | 0.0074 | | 0.0204 | -0.0327 | 0.0474 |
| HOWN_good | 0.0482 | *** | 0.0168 | 0.0153 | 0.0810 |
| DWNPAY_prev_home | 0.1418 | *** | 0.0145 | 0.1133 | 0.1703 |
+------------------+-----------------+--------------+------------+--------------+--------------+The marginal effect of first time homebuyers (FRSTHO) is \(-0.0739\). This shows that first time home buyers are 7.39% less likely to make a 20% down payment.
The marginal effect of the number of bedrooms (BEDRMS) is \(-0.0184\). This shows that an additional bedroom is associated with a 1.84% lower probability of making a 20% down payment.
Adding Interaction Terms
Let’s take a closer look at the relationship between number of bedrooms, first-time homebuyers, and the probability of making a 20%+ down payment. To do this, we will fit a new Logistic Regression Model using all the previously included predictors, plus the interaction between first-time homebuyers, FRSTHO, and number of bedrooms, BEDRMS. This will allow us to interpret how the relationship between the number of bedrooms and the probability of making a 20%+ down payment varies depending on whether the buyer is a first-time homebuyer.
Interaction Between FRSTHO and BEDRMS
interaction_cols_FRSTHO_BEDRMS = add_interaction_terms(['FRSTHO'], ['BEDRMS'])New Logistic Regression (with Interaction Terms)
assembler_predictors = (
conti_cols_2 +
dummy_cols +
interaction_cols_FRSTHO_BEDRMS
)
assembler_4 = VectorAssembler(
inputCols = assembler_predictors,
outputCol = "predictors"
)
dtrain_4 = assembler_4.transform(dtrain)
dtest_4 = assembler_4.transform(dtest)# training the model
model_4 = (
GeneralizedLinearRegression(featuresCol="predictors",
labelCol="GT20DOWN",
family="binomial",
link="logit")
.fit(dtrain_4)
)dtrain_4 = model_4.transform(dtrain_4)
dtest_4 = model_4.transform(dtest_4)model_4.summaryCoefficients:
Feature Estimate Std Error T Value P Value
(Intercept) 0.5973 0.2126 2.8099 0.0050
ZINC2 0.0000 0.0000 0.8195 0.4125
BATHS 0.2829 0.0408 6.9307 0.0000
BEDRMS -0.0322 0.0406 -0.7929 0.4278
NUNITS 0.0126 0.0060 2.0798 0.0375
EJUNK -0.2374 0.1721 -1.3793 0.1678
ESFD -0.2240 0.0995 -2.2500 0.0244
ETRANS -0.1363 0.0844 -1.6158 0.1061
EABAN -0.3890 0.1205 -3.2279 0.0012
INTW -0.0684 0.0148 -4.6252 0.0000
FRSTHO 0.0198 0.1860 0.1066 0.9151
STATE_CO -0.1957 0.0984 -1.9878 0.0468
STATE_CT 0.7175 0.1092 6.5688 0.0000
STATE_GA 0.0121 0.1039 0.1167 0.9071
STATE_IL 0.3454 0.1938 1.7820 0.0748
STATE_IN 0.2013 0.1031 1.9519 0.0509
STATE_LA 0.4578 0.1255 3.6480 0.0003
STATE_MO 0.2041 0.1155 1.7673 0.0772
STATE_OH 0.5293 0.1116 4.7445 0.0000
STATE_OK 0.0965 0.1092 0.8835 0.3770
STATE_PA 0.2544 0.1147 2.2174 0.0266
STATE_TX 0.1285 0.1147 1.1201 0.2627
STATE_WA 0.1046 0.1042 1.0044 0.3152
METRO_urban 0.0646 0.0603 1.0714 0.2840
HHGRAD_Assoc -0.6796 0.0783 -8.6746 0.0000
HHGRAD_Grad -0.0526 0.0764 -0.6876 0.4917
HHGRAD_HS_Grad -0.6788 0.0579 -11.7180 0.0000
HHGRAD_No_HS -0.8770 0.0977 -8.9786 0.0000
HOWH_good 0.0339 0.0871 0.3892 0.6971
HOWN_good 0.2036 0.0715 2.8474 0.0044
DWNPAY_prev_home 0.5951 0.0622 9.5746 0.0000
FRSTHO_*_BEDRMS -0.1076 0.0569 -1.8905 0.0587
(Dispersion parameter for binomial family taken to be 1.0000)
Null deviance: 12511.4865 on 9319 degrees of freedom
Residual deviance: 11486.2166 on 9319 degrees of freedom
AIC: 11550.2166The coefficient of the interaction term between first time homebuyers (FRSTHO) and number of bedrooms (BEDRMS) is \(-0.1076\). This means that for first time homebuyers, each additional bedroom decreases the chance that the homebuyer will make a 20% down payment by 0.1076 units.
Marginal Effects
# Compute means
means_df = dtrain_4.select([mean(col).alias(col) for col in assembler_predictors])
# Collect the results as a list
means = means_df.collect()[0]
means_list = [means[col] for col in assembler_predictors]table_output, df_ME = marginal_effects(model_4, means_list) # Instead of mean values, some other representative values can also be chosen.
print(table_output)+------------------+-----------------+--------------+------------+--------------+--------------+
| Variable | Marginal Effect | Significance | Std. Error | 95% CI Lower | 95% CI Upper |
+------------------+-----------------+--------------+------------+--------------+--------------+
| ZINC2 | 0.0000 | | 0.0000 | -0.0000 | 0.0000 |
| BATHS | 0.0664 | *** | 0.0096 | 0.0476 | 0.0852 |
| BEDRMS | -0.0076 | | 0.0095 | -0.0262 | 0.0111 |
| NUNITS | 0.0029 | ** | 0.0014 | 0.0002 | 0.0057 |
| EJUNK | -0.0557 | | 0.0404 | -0.1349 | 0.0235 |
| ESFD | -0.0526 | ** | 0.0234 | -0.0983 | -0.0068 |
| ETRANS | -0.0320 | | 0.0198 | -0.0708 | 0.0068 |
| EABAN | -0.0913 | *** | 0.0283 | -0.1467 | -0.0358 |
| INTW | -0.0160 | *** | 0.0035 | -0.0228 | -0.0092 |
| FRSTHO | 0.0047 | | 0.0436 | -0.0809 | 0.0902 |
| STATE_CO | -0.0459 | ** | 0.0231 | -0.0912 | -0.0006 |
| STATE_CT | 0.1684 | *** | 0.0256 | 0.1181 | 0.2186 |
| STATE_GA | 0.0028 | | 0.0244 | -0.0449 | 0.0506 |
| STATE_IL | 0.0810 | * | 0.0455 | -0.0081 | 0.1702 |
| STATE_IN | 0.0472 | * | 0.0242 | -0.0002 | 0.0947 |
| STATE_LA | 0.1074 | *** | 0.0294 | 0.0497 | 0.1651 |
| STATE_MO | 0.0479 | * | 0.0271 | -0.0052 | 0.1010 |
| STATE_OH | 0.1242 | *** | 0.0262 | 0.0729 | 0.1755 |
| STATE_OK | 0.0226 | | 0.0256 | -0.0276 | 0.0729 |
| STATE_PA | 0.0597 | ** | 0.0269 | 0.0069 | 0.1125 |
| STATE_TX | 0.0301 | | 0.0269 | -0.0226 | 0.0829 |
| STATE_WA | 0.0245 | | 0.0244 | -0.0234 | 0.0724 |
| METRO_urban | 0.0151 | | 0.0141 | -0.0126 | 0.0429 |
| HHGRAD_Assoc | -0.1595 | *** | 0.0184 | -0.1955 | -0.1234 |
| HHGRAD_Grad | -0.0123 | | 0.0179 | -0.0475 | 0.0228 |
| HHGRAD_HS_Grad | -0.1593 | *** | 0.0136 | -0.1859 | -0.1326 |
| HHGRAD_No_HS | -0.2058 | *** | 0.0229 | -0.2507 | -0.1609 |
| HOWH_good | 0.0080 | | 0.0204 | -0.0321 | 0.0480 |
| HOWN_good | 0.0478 | *** | 0.0168 | 0.0149 | 0.0807 |
| DWNPAY_prev_home | 0.1396 | *** | 0.0146 | 0.1110 | 0.1682 |
| FRSTHO_*_BEDRMS | -0.0253 | * | 0.0134 | -0.0514 | 0.0009 |
+------------------+-----------------+--------------+------------+--------------+--------------+The marginal effect of the interaction term between first time homebuyers (FRSTHO) and number of bedrooms (BEDRMS) is \(-0.0253\). This means that for each additional bedroom, first time homebuyers are 2.53% less likely to make a 20% down payment compared to non-first time homebuyers.
Two More Logistic Regression Models
Finally, we will fit two more Logistic Regression Models in order to predict home value for two subsets of home data. One subset and model will feature only homes worth greater than or equal to 175k. The other subset will feature homes worth less than 175k. We can compare the models’ residual deviance, \(RMSE\), and classification performance to evaluate whether or not performance changes for different home value levels.
Split DataFrame
greater_than_equal_175000 = df[df['VALUE'] >= 175000]
less_than_175000 = df[df['VALUE'] < 175000]Homes worth VALUE ≥ 175k
Split into Training/Testing
dtrain, dtest = greater_than_equal_175000.randomSplit([0.6, 0.4], seed=1234)Dummy Variables
dummy_cols_STATE, ref_category_STATE = add_dummy_variables('STATE', 0)
dummy_cols_METRO, ref_category_METRO = add_dummy_variables('METRO', 0)
dummy_cols_HHGRAD, ref_category_HHGRAD = add_dummy_variables('HHGRAD', 1)
dummy_cols_HOWH, ref_category_HOWH = add_dummy_variables('HOWH', 0)
dummy_cols_HOWN, ref_category_HOWN = add_dummy_variables('HOWN', 0)
dummy_cols_DWNPAY, ref_category_DWNPAY = add_dummy_variables('DWNPAY', 0)Reference category (dummy omitted): CA
Reference category (dummy omitted): rural
Reference category (dummy omitted): Bach
Reference category (dummy omitted): bad
Reference category (dummy omitted): bad
Reference category (dummy omitted): otherLogistic Regression Model
assembler_predictors = (
conti_cols_2 +
dummy_cols
)
assembler_5 = VectorAssembler(
inputCols = assembler_predictors,
outputCol = "predictors"
)
dtrain_5 = assembler_5.transform(dtrain)
dtest_5 = assembler_5.transform(dtest)# training the model
model_5 = (
GeneralizedLinearRegression(featuresCol="predictors",
labelCol="GT20DOWN",
family="binomial",
link="logit")
.fit(dtrain_5)
)dtrain_5 = model_5.transform(dtrain_5)
dtest_5 = model_5.transform(dtest_5)model_5.summaryCoefficients:
Feature Estimate Std Error T Value P Value
(Intercept) 0.6684 0.3251 2.0562 0.0398
ZINC2 0.0000 0.0000 -0.0764 0.9391
BATHS 0.3301 0.0567 5.8208 0.0000
BEDRMS -0.1040 0.0465 -2.2361 0.0253
NUNITS 0.0234 0.0134 1.7432 0.0813
EJUNK -0.5695 0.3093 -1.8415 0.0656
ESFD -0.3985 0.1853 -2.1513 0.0315
ETRANS -0.1742 0.1410 -1.2356 0.2166
EABAN -0.6480 0.2510 -2.5822 0.0098
INTW -0.0567 0.0275 -2.0606 0.0393
FRSTHO -0.3161 0.0888 -3.5608 0.0004
STATE_CO -0.0415 0.1061 -0.3908 0.6959
STATE_CT 0.8530 0.1275 6.6922 0.0000
STATE_GA 0.2964 0.1367 2.1676 0.0302
STATE_IL 0.4020 0.4308 0.9331 0.3508
STATE_IN 0.7344 0.1791 4.1011 0.0000
STATE_LA 0.7326 0.2326 3.1494 0.0016
STATE_MO 0.8763 0.1818 4.8199 0.0000
STATE_OH 0.7728 0.1790 4.3168 0.0000
STATE_OK 1.0786 0.2655 4.0626 0.0000
STATE_PA 0.7274 0.2256 3.2237 0.0013
STATE_TX 0.6446 0.2659 2.4241 0.0153
STATE_WA 0.2529 0.1120 2.2579 0.0240
METRO_urban -0.0364 0.0961 -0.3785 0.7051
HHGRAD_Assoc -0.6786 0.1142 -5.9400 0.0000
HHGRAD_Grad 0.0146 0.0994 0.1471 0.8830
HHGRAD_HS_Grad -0.5142 0.0840 -6.1181 0.0000
HHGRAD_No_HS -0.8903 0.1717 -5.1846 0.0000
HOWH_good -0.1540 0.1552 -0.9925 0.3209
HOWN_good 0.4110 0.1202 3.4188 0.0006
DWNPAY_prev_home 0.5943 0.0853 6.9678 0.0000
(Dispersion parameter for binomial family taken to be 1.0000)
Null deviance: 5908.5931 on 4680 degrees of freedom
Residual deviance: 5328.8668 on 4680 degrees of freedom
AIC: 5390.8668# Compute confusion matrix
dtest_5 = dtest_5.withColumn("predicted_class", when(col("prediction") > .02, 1).otherwise(0))
conf_matrix = dtest_5.groupBy("GT20DOWN", "predicted_class").count().orderBy("GT20DOWN", "predicted_class")
TP = dtest_5.filter((col("GT20DOWN") == 1) & (col("predicted_class") == 1)).count()
FP = dtest_5.filter((col("GT20DOWN") == 0) & (col("predicted_class") == 1)).count()
FN = dtest_5.filter((col("GT20DOWN") == 1) & (col("predicted_class") == 0)).count()
TN = dtest_5.filter((col("GT20DOWN") == 0) & (col("predicted_class") == 0)).count()
accuracy = (TP + TN) / (TP + FP + FN + TN)
precision = TP / (TP + FP)
recall = TP / (TP + FN)
specificity = TN / (TN + FP)
average_rate = (TP + FN) / (TP + TN + FP + FN) # Proportion of actual at-risk babies
enrichment = precision / average_rate
# Print formatted confusion matrix with labels
print("\n Confusion Matrix:\n")
print(" Predicted")
print(" | Negative | Positive ")
print("------------+------------+------------")
print(f"Actual Neg. | {TN:5} | {FP:5} |")
print("------------+------------+------------")
print(f"Actual Pos. | {FN:5} | {TP:5} |")
print("------------+------------+------------")
print(f"Accuracy: {accuracy:.4f}")
print(f"Precision: {precision:.4f}")
print(f"Recall (Sensitivity): {recall:.4f}")
print(f"Specificity: {specificity:.4f}")
print(f"Average Rate: {average_rate:.4f}")
print(f"Enrichment: {enrichment:.4f} (Relative Precision)")
Confusion Matrix:
Predicted
| Negative | Positive
------------+------------+------------
Actual Neg. | 0 | 960 |
------------+------------+------------
Actual Pos. | 0 | 2160 |
------------+------------+------------
Accuracy: 0.6923
Precision: 0.6923
Recall (Sensitivity): 1.0000
Specificity: 0.0000
Average Rate: 0.6923
Enrichment: 1.0000 (Relative Precision)AUC and ROC
# Use probability of the positive class (y=1)
evaluator = BinaryClassificationEvaluator(labelCol="GT20DOWN", rawPredictionCol="prediction", metricName="areaUnderROC")
# Evaluate AUC
auc = evaluator.evaluate(dtest_5)
print(f"AUC: {auc:.4f}") # Higher is better (closer to 1)
# Convert to Pandas
pdf = dtest_5.select("prediction", "GT20DOWN").toPandas()
# Compute ROC curve
fpr, tpr, _ = roc_curve(pdf["GT20DOWN"], pdf["prediction"])
# Plot ROC curve
plt.figure(figsize=(8,6))
plt.plot(fpr, tpr, label=f"ROC Curve (AUC = {auc:.4f})")
plt.plot([0, 1], [0, 1], 'k--', label="Random Guess")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve")
plt.legend()
plt.show()AUC: 0.6741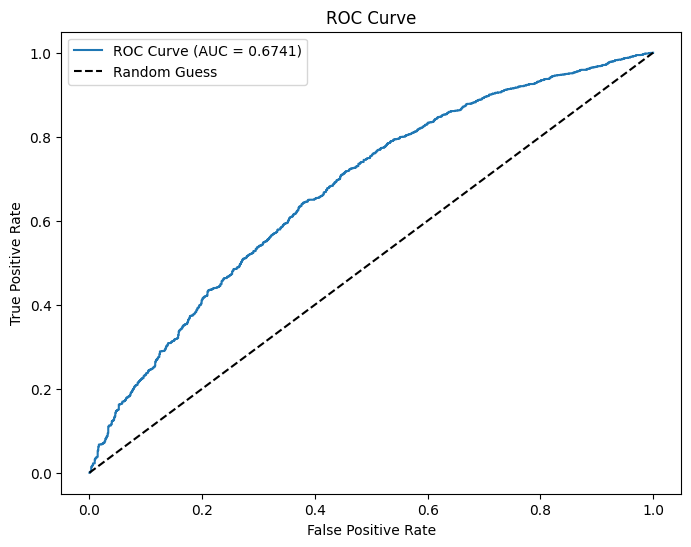
Homes worth VALUE < 175k
dtrain, dtest = less_than_175000.randomSplit([0.6, 0.4], seed=1234)dummy_cols_STATE, ref_category_STATE = add_dummy_variables('STATE', 0)
dummy_cols_METRO, ref_category_METRO = add_dummy_variables('METRO', 0)
dummy_cols_HHGRAD, ref_category_HHGRAD = add_dummy_variables('HHGRAD', 1)
dummy_cols_HOWH, ref_category_HOWH = add_dummy_variables('HOWH', 0)
dummy_cols_HOWN, ref_category_HOWN = add_dummy_variables('HOWN', 0)
dummy_cols_DWNPAY, ref_category_DWNPAY = add_dummy_variables('DWNPAY', 0)Reference category (dummy omitted): CA
Reference category (dummy omitted): rural
Reference category (dummy omitted): Bach
Reference category (dummy omitted): bad
Reference category (dummy omitted): bad
Reference category (dummy omitted): otherassembler_predictors = (
conti_cols_2 +
dummy_cols
)
assembler_6 = VectorAssembler(
inputCols = assembler_predictors,
outputCol = "predictors"
)
dtrain_6 = assembler_6.transform(dtrain)
dtest_6 = assembler_6.transform(dtest)# training the model
model_6 = (
GeneralizedLinearRegression(featuresCol="predictors",
labelCol="GT20DOWN",
family="binomial",
link="logit")
.fit(dtrain_6)
)dtrain_6 = model_6.transform(dtrain_6)
dtest_6 = model_6.transform(dtest_6)model_6.summaryCoefficients:
Feature Estimate Std Error T Value P Value
(Intercept) 1.0004 0.3609 2.7724 0.0056
ZINC2 0.0000 0.0000 2.4733 0.0134
BATHS 0.2564 0.0641 4.0021 0.0001
BEDRMS -0.1801 0.0469 -3.8381 0.0001
NUNITS 0.0288 0.0117 2.4521 0.0142
EJUNK -0.4302 0.2098 -2.0506 0.0403
ESFD -0.1264 0.1233 -1.0256 0.3051
ETRANS -0.0607 0.1006 -0.6037 0.5461
EABAN -0.2049 0.1320 -1.5520 0.1207
INTW -0.0681 0.0177 -3.8552 0.0001
FRSTHO -0.2598 0.0747 -3.4807 0.0005
STATE_CO -0.1942 0.3192 -0.6083 0.5430
STATE_CT 0.5233 0.3094 1.6911 0.0908
STATE_GA -0.4573 0.2993 -1.5280 0.1265
STATE_IL 0.2285 0.3448 0.6625 0.5076
STATE_IN -0.1152 0.2925 -0.3939 0.6936
STATE_LA 0.1373 0.3037 0.4520 0.6513
STATE_MO -0.2127 0.3007 -0.7074 0.4793
STATE_OH 0.3449 0.2978 1.1583 0.2468
STATE_OK -0.1493 0.2936 -0.5086 0.6110
STATE_PA 0.0185 0.2978 0.0621 0.9505
STATE_TX 0.0126 0.2965 0.0425 0.9661
STATE_WA 0.2563 0.3452 0.7425 0.4578
METRO_urban -0.0106 0.0778 -0.1367 0.8913
HHGRAD_Assoc -0.5577 0.1074 -5.1936 0.0000
HHGRAD_Grad 0.0209 0.1275 0.1640 0.8697
HHGRAD_HS_Grad -0.5503 0.0821 -6.7068 0.0000
HHGRAD_No_HS -0.7198 0.1241 -5.7995 0.0000
HOWH_good 0.1855 0.1070 1.7341 0.0829
HOWN_good -0.0093 0.0888 -0.1051 0.9163
DWNPAY_prev_home 0.4973 0.0946 5.2586 0.0000
(Dispersion parameter for binomial family taken to be 1.0000)
Null deviance: 6427.1456 on 4622 degrees of freedom
Residual deviance: 6060.5538 on 4622 degrees of freedom
AIC: 6122.5538# Compute confusion matrix
dtest_6 = dtest_6.withColumn("predicted_class", when(col("prediction") > .02, 1).otherwise(0))
conf_matrix = dtest_6.groupBy("GT20DOWN", "predicted_class").count().orderBy("GT20DOWN", "predicted_class")
TP = dtest_6.filter((col("GT20DOWN") == 1) & (col("predicted_class") == 1)).count()
FP = dtest_6.filter((col("GT20DOWN") == 0) & (col("predicted_class") == 1)).count()
FN = dtest_6.filter((col("GT20DOWN") == 1) & (col("predicted_class") == 0)).count()
TN = dtest_6.filter((col("GT20DOWN") == 0) & (col("predicted_class") == 0)).count()
accuracy = (TP + TN) / (TP + FP + FN + TN)
precision = TP / (TP + FP)
recall = TP / (TP + FN)
specificity = TN / (TN + FP)
average_rate = (TP + FN) / (TP + TN + FP + FN) # Proportion of actual at-risk babies
enrichment = precision / average_rate
# Print formatted confusion matrix with labels
print("\n Confusion Matrix:\n")
print(" Predicted")
print(" | Negative | Positive ")
print("------------+------------+------------")
print(f"Actual Neg. | {TN:5} | {FP:5} |")
print("------------+------------+------------")
print(f"Actual Pos. | {FN:5} | {TP:5} |")
print("------------+------------+------------")
print(f"Accuracy: {accuracy:.4f}")
print(f"Precision: {precision:.4f}")
print(f"Recall (Sensitivity): {recall:.4f}")
print(f"Specificity: {specificity:.4f}")
print(f"Average Rate: {average_rate:.4f}")
print(f"Enrichment: {enrichment:.4f} (Relative Precision)")
Confusion Matrix:
Predicted
| Negative | Positive
------------+------------+------------
Actual Neg. | 0 | 1422 |
------------+------------+------------
Actual Pos. | 0 | 1659 |
------------+------------+------------
Accuracy: 0.5385
Precision: 0.5385
Recall (Sensitivity): 1.0000
Specificity: 0.0000
Average Rate: 0.5385
Enrichment: 1.0000 (Relative Precision)AUC and ROC
# Use probability of the positive class (y=1)
evaluator = BinaryClassificationEvaluator(labelCol="GT20DOWN", rawPredictionCol="prediction", metricName="areaUnderROC")
# Evaluate AUC
auc = evaluator.evaluate(dtest_6)
print(f"AUC: {auc:.4f}") # Higher is better (closer to 1)
# Convert to Pandas
pdf = dtest_6.select("prediction", "GT20DOWN").toPandas()
# Compute ROC curve
fpr, tpr, _ = roc_curve(pdf["GT20DOWN"], pdf["prediction"])
# Plot ROC curve
plt.figure(figsize=(8,6))
plt.plot(fpr, tpr, label=f"ROC Curve (AUC = {auc:.4f})")
plt.plot([0, 1], [0, 1], 'k--', label="Random Guess")
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("ROC Curve")
plt.legend()
plt.show()AUC: 0.6519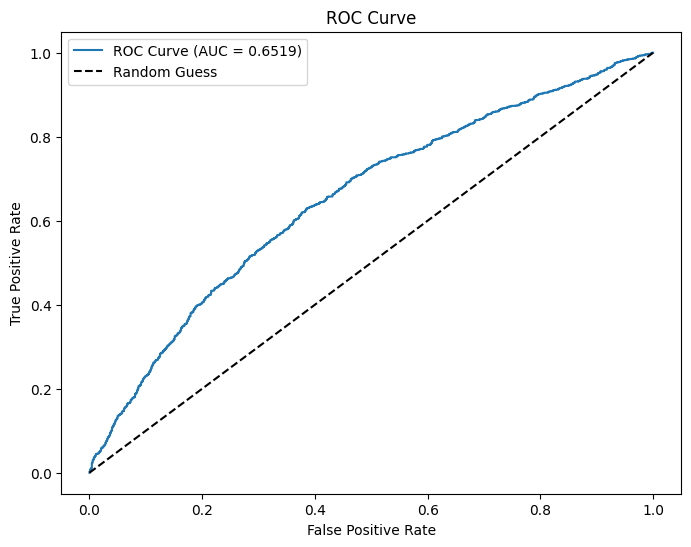
Interpretation
The logistic regression model for houses with a value of 175k or greater has a residual deviance of \(5328.8668\). The model for houses with a value of less than 175k has a residual deviance of \(6060.5538\). This shows that the model for houses with a value of 175k or greater fits the data better because it has a lower residual deviance. In other words, the predictors more accurately predict if the homebuyer makes a 20% down payment for houses with a value of 175k or greater.
The model for houses with a value of 175k or higher has an accuracy of \(0.6923\), whereas the model for houses with a value of less than 175k has an accuracy of \(0.5385\). Once again, the model for higher value houses makes more accurate predictions because of its higher accuracy.
The AUC of the model for houses with greater value is \(0.6741\). The AUC of the model for lower value houses is \(0.6519\). The AUC for the model with higher value houses is slightly closer to 1 than the model with lower value houses. This supports the previous two claims that the model with higher value houses more accurately predicts if the homebuyer makes a 20% down payment.